
JavaScript 原型链污染
ns碰到的两道题目 来学习一下
JavaScript 原型链污染
什么是原型污染
首先来简单说一下原型是什么
在 JavaScript 中,原型是一种实现继承的机制
每个对象都有一个 prototype 属性(除了null)。它指向另一个对象,这个被指向的对象就是原型对象。当访问一个对象的属性时,如果该对象本身没有这个属性,JavaScript 引擎就会沿着原型链向上查找,直到找到该属性或者到达原型链的顶端(null)。
look this
1 | function Person(name) { |
Person.prototype 就是一个原型对象,sayHello 方法定义在原型对象上。alice 实例本身没有 sayHello 方法,但通过原型链,它可以访问到 Person.prototype 上的 sayHello 方法。
原型链污染
就是指攻击者利用这个原型机制 向全局对象的原型添加任意的属性
因为js中对象会通过这个原型链继承对应的属性 所以当全局原型被污染时 后面创建的所有对象都会继承这些恶意添加的属性
通俗点来说就是攻击者偷摸改了大家通用的那个模板 然后所有通过这个模板创建的新对象都带上了攻击者加进去的东西
原型链污染又分为客户端原型链污染和服务端原型链污染
客户端环境通常指的是浏览器环境
服务端环境一般指 Node.js 环境,Node.js 用于构建服务器端应用程序,处理网络请求、数据库操作等。当应用程序处理用户输入的 JSON 数据、表单数据等时,如果没有对输入进行严格过滤,就容易出现原型链污染
在ctf中基本都是服务端污染导致绕过验证,得到管理员权限或者RCE等等
不同类型对象原型示例
普通对象
1 | let myObject = {}; |
使用 let myObject = {}; 创建一个空对象。通过 Object.getPrototypeOf(myObject); 可以获取它的原型,结果是 Object.prototype 。这意味着,myObject 这个空对象继承自 Object.prototype ,它可以访问 Object.prototype 上的属性和方法
字符串对象
1 | let myString = ""; |
当使用 let myString = ""; 创建一个空字符串时,通过 Object.getPrototypeOf(myString); 获取到它的原型是 String.prototype 。String.prototype 上定义了许多实用的方法,像 toLowerCase() 、toUpperCase() 、indexOf() 等
数组对象
1 | let myArray = []; |
用 let myArray = []; 创建一个空数组,Object.getPrototypeOf(myArray); 返回 Array.prototype 。Array.prototype 提供了诸如 push() 、pop() 、map() 、filter() 等方法,方便对数组进行操作
数值对象
1 | let myNumber = 1; |
对于 let myNumber = 1; 创建的数值,Object.getPrototypeOf(myNumber); 得到 Number.prototype ,Number.prototype 上有 toFixed() 、toString() 等方法
对象会自动继承其指定原型的所有属性,除非它们已经拥有具有相同键的自己的属性。这使得开发人员能够创建可以重用现有对象的属性和方法的新对象
来看一个栗子
比如,有一个原型对象 animalPrototype
1 | let animalPrototype = { |
这里 dog 对象通过 Object.create(animalPrototype) 创建,它继承了 animalPrototype 上的 speak 方法。但如果在 dog 对象上定义了同名方法,就会覆盖从原型继承来的方法:
1 | let animalPrototype = { |
(还是比较容易理解的)
原型链
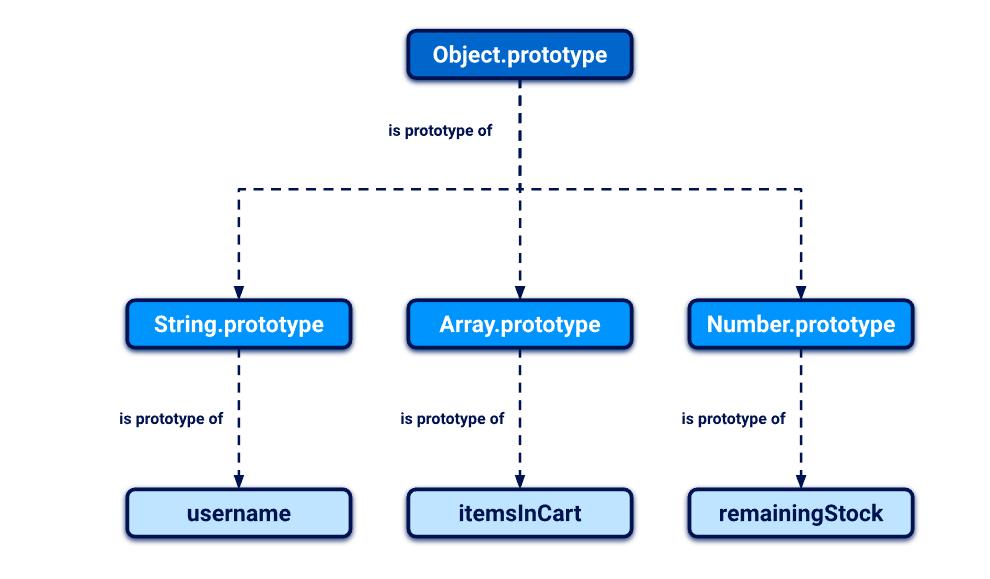
原型链的链式继承逻辑
JavaScript 里,每个对象都有一个 “原型”(可以理解为 “父对象”),而这个原型对象本身也是一个对象,它也有自己的原型 —— 以此类推,就形成了一条 “原型链”。
比如图中的 username(字符串对象),它的直接原型是 String.prototype;
而 String.prototype 的原型是 Object.prototype;
Object.prototype是原型链的 “顶端”,它的原型是 null(表示没有更上层的原型了)。
属性查找规则
当你访问一个对象的属性 / 方法时,JavaScript 会先在对象自身找;如果找不到,就会沿着原型链往上找,直到找到属性 / 方法,或者到达原型链顶端(null)。
所有原型链最终都会指向 Object.prototype,而 Object.prototype 的原型是 null—— 这是原型链的 “终点”,表示没有更上层的原型了。
总的来说
原型链是 JavaScript 实现 “继承” 的核心机制它让对象能层层继承上层原型的能力,同时也解释了 “为什么不同类型的对象能调用各自的专属方法”
使用 __proto__ 访问对象的原型
每个 JavaScript 对象都有一个特殊的属性__proto__ 它可以用来访问对象的原型
和访问对象的普通属性一样,可以使用点符号或者方括号来访问 __proto__:
点符号:username.__proto__
方括号:username['__proto__']
比如
username.__proto__:得到的是 String.prototype,因为 username 是字符串对象,它的直接原型是 String.prototype。
1 | username.__proto__ // String.prototype |
原型的修改
JavaScript 里的内置原型(像 String.prototype、Array.prototype )本质上也就是普通对象。所以我们可以像修改普通对象一样,去修改这些内置原型的属性或方法
那么这就意味着你可以自定义新方法或者重写已有的方法
现代 JavaScript 有 trim() 方法(用于删除字符串首尾空格),但在早期版本中没有这个方法。那时候,开发者会通过修改 String.prototype 来 “手动添加” 类似功能:
1 | // 给 String.prototype 新增一个 remove方法 |
因为 JavaScript 是原型继承,所以只要你修改了某个 “原型”,所有继承自该原型的对象都会自动获得修改后的能力。
原型污染漏洞是如何产生的
当 JavaScript 函数递归地将用户可控制的对象合并到现有对象时,若没有先对属性键(尤其是特殊键 __proto__)做清理,就会引发原型污染。
__proto__ 是 JavaScript 中用于访问对象原型的特殊属性。
若合并逻辑未过滤 __proto__,攻击者可通过它将属性注入到原型对象(而非目标对象本身)
污染任何原型对象都有可能,但这最常发生在内置的全局 Object.prototype 上。
prototype 与 __proto__
prototype
在 JavaScript 里,函数都有一个 prototype 属性,它是一个对象。当使用构造函数创建实例时,这些实例会共享构造函数 prototype 对象上的属性和方法, 是实现原型继承的基础。
1 | function Person(name) { |
在这个栗子中,Person 是一个构造函数,Person.prototype 是一个对象,在 Person.prototype 上定义了 sayHello 方法。通过 new Person('Alice') 创建的实例 alice ,可以访问 Person.prototype 上的 sayHello 方法,这就是利用 prototype 实现继承的过程。
__proto__
每个对象(除了 null )都有一个 __proto__ 属性,它指向该对象的原型对象, 可以用来访问对象的原型,是沿着原型链查找属性和方法的关键。虽然 __proto__ 是大多数浏览器事实上使用的标准,但它并不是正式标准化的属性(ES6 引入了 Object.getPrototypeOf() 方法来更规范地获取对象的原型)。
1 | let myObject = {}; |
通过 __proto__ 可以明确对象和其原型之间的关系,并且可以通过 __proto__ 层层向上访问原型链上的属性和方法
1 | let str = "hello"; |
通过 prototype 为构造函数设置的属性和方法,实例可以通过 __proto__ 来访问,从而实现原型继承
联系
当使用构造函数创建对象时,实例的 __proto__ 会指向构造函数的 prototype 。:
1 | function Animal() {} |
这表明,通过 prototype 为构造函数设置的属性和方法,实例可以通过 __proto__ 来访问,从而实现了原型继承。
区别
所属对象不同:prototype 是函数特有的属性,只有函数才有 prototype;而 __proto__ 是对象(除 null 外)都有的属性。
用途不同:prototype 主要用于在构造函数中为实例预先设置共享的属性和方法,实现代码复用;__proto__ 主要用于在运行时动态地访问对象的原型,沿着原型链查找属性和方法。
标准化程度不同:prototype 是 JavaScript 中被正式定义和标准化的属性;而 __proto__ 虽然被广泛支持,但不是严格标准化的属性,在规范中更推荐使用 Object.getPrototypeOf() 等方法来获取对象的原型。
通过 JSON 输入造成原型污染
JSON.parse()
JSON.parse() 在解析 JSON 字符串时,会把 __proto__ 当作普通的字符串键,而不是 “原型访问器”
再来举个例子
1 | // 情况1:对象字面量中的 __proto__(特殊行为) |
这会导致原型污染
如果后续代码中,对 objectFromJson 进行对象合并 / 赋值,且没有过滤 __proto__ 这个键,就可能污染原型:假设存在一个 “不安全的合并函数”:
1 | function merge(target, source) { |
此时,merge 函数会执行 target["__proto__"] = { evilProperty: "payload" }。由于 target["__proto__"] 就是 target 的原型(Object.prototype),最终会导致:
Object.prototype.evilProperty = "payload"。
这意味着所有对象(因为所有对象都继承自 Object.prototype)都会 “继承” evilProperty 属性,从而被污染。
1 | const objectLiteral = {__proto__: {evilProperty: 'payload'}}; |
在Node.js中,hasOwnProperty函数是JavaScript中的一个内置函数,用于检查对象自身是否包含指定的属性(即不包括从原型链继承的属性)。这个函数返回一个布尔值,如果对象包含指定的属性,则返回true,否则返回false
1 | function merge(target, source) { |
第一步
object2 经过 JSON.parse() 解析后,结构为:
1 | { |
1 | console.log(object2.hasOwnProperty('__proto__')); // true(证明是自身属性) |
第二步
执行 merge (object1, object2) 函数
merge 函数的作用是将 source(object2)的属性合并到 target(object1)中,核心逻辑是递归处理嵌套属性。
第一次循环:处理 key = “a”
source是 object2,key 是 “a”。
判断 key in source(object2 有 “a” → 真)和 key in target(object1 是空对象,没有 “a” → 假)。
进入 else 分支:target[key] = source[key] → object1.a = 1。
此时 object1 变为 { a: 1 }。
*第二次循环:处理 key = “*proto*“*
key 是 “proto“,source[key] 是 { b: 2 }(object2 自身的 proto 属性值)。
判断 key in source(object2 有 “proto“ 自身属性 → 真)和 key in target(object1 作为对象,默认有 __proto__ 原型访问器 → 真)。
进入递归:merge(target[key], source[key]) → 即 merge(object1.__proto__, { b: 2 })。
第三步
*递归执行 merge (object1.*proto*, { b: 2 })*
此时:
target是 object1.__proto__→ 即 Object.prototype(所有对象的顶层原型)。
source是{ b: 2 }。
循环处理 source 的属性 key = "b":
判断 key in source(有 “b” → 真)和 key in target(Object.prototype 原本没有 “b” → 假)。
进入 else 分支:target[key] = source[key] → Object.prototype.b = 2。
关键结论:Object.prototype 被污染,新增了 b: 2 属性。
JSON.parse () 的作用:将 __proto__ 解析为对象自身属性,而非原型访问器,提供了污染入口。
merge 函数的漏洞:未过滤 __proto__ 特殊键,递归合并时修改了 Object.prototype。
污染范围:Object.prototype 被污染后,所有对象(包括新创建的对象、字符串等)都会继承恶意属性 b: 2。
这就是典型的 “通过 JSON 输入 + 不安全合并函数” 实现原型污染的完整流程
题目
[NewStarCTF 2023 公开赛道]OtenkiGirl
先下载附件
看到app.js
1 | const env = global.env = (process.env.NODE_ENV || "production").trim(); |
把这个拿出来看一下
1 | //这里引入了route文件夹下的info 和route |
这段代码的目的是批量加载并注册路由,让 Koa 应用能处理不同 URL 路径的请求。
(不懂没事 继续往下)
[ "info", "submit" ]:
这是一个字符串数组,包含需要加载的路由模块名称(info 和 submit)。
.forEach(p => { ... }):
遍历数组中的每个元素(p 依次为 "info"、"submit"),对每个元素执行回调逻辑
p = require("./routes/" + p):
“./routes/“ + p会拼接出路由文件的路径(如 “./routes/info”、”./routes/submit”`)。
require会加载对应路径的模块(假设是 info.js和 submit.js),并将模块赋值给 p。
app.use(p.routes()).use(p.allowedMethods()):
p.routes():获取路由模块中定义的路由规则(如哪些 URL 对应哪些处理函数)。
p.allowedMethods():配置允许的 HTTP 请求方法(如限制接口只接受 GET/POST,若请求方法不允许则返回错误)。
app.use(...):将路由规则和请求方法限制注册到 Koa 应用中,使应用能响应对应请求
因此我们追踪到routes文件下的info.js和submit.js
info.js代码
1 | const Router = require("koa-router"); |
我们注意到这段代码let minTimestamp = new Date(CONFIG.min_public_time || DEFAULT_CONFIG.min_public_time).getTime();,
将我们传入的timestamp做了一个过滤,使得所返回的数据不早于配置文件中的min_public_time
意思是使用 CONFIG 变量中的 min_public_time 属性(如果存在),否则使用 DEFAULT_CONFIG 变量中的 min_public_time 属性。
我们继续找config文件和config.default文件,发现CONFIG 变量中没有min_public_time 属性,所以会使用DEFAULT_CONFIG 变量中的 min_public_time 属性。
config.default文件
1 | module.exports = { |
我们这里可以原型链污染污染min_public_time为更早的日期,尝试绕过这个日期限制。
submit.js代码(有点多 这里就放出来一部分重要的)
这里可以发现注入点
1 | const merge = (dst, src) => { |
merge 函数的目的是递归合并两个对象(将 src 的属性合并到 dst 中)
这个 merge 函数没有过滤特殊键(如 __proto__)
我们注意到在第7行中,如果key既存在于dst对象中,又存在于src对象中,则会递归调用merge函数将它们合并,否则dst[key]会被赋值为src[key]。
这意味着如果src对象的原型链上存在名为’min_public_time’的属性,则该属性将被赋值给dst对象,那么dst[key]将会指向原型链上的值。在JavaScript中,对象可以具有特殊的属性__proto__,它指向对象的原型。通过修改data['__proto__']['min_public_time']的值,我们可以影响原型链上的属性。
思路有了我们来解题
改一下时间戳
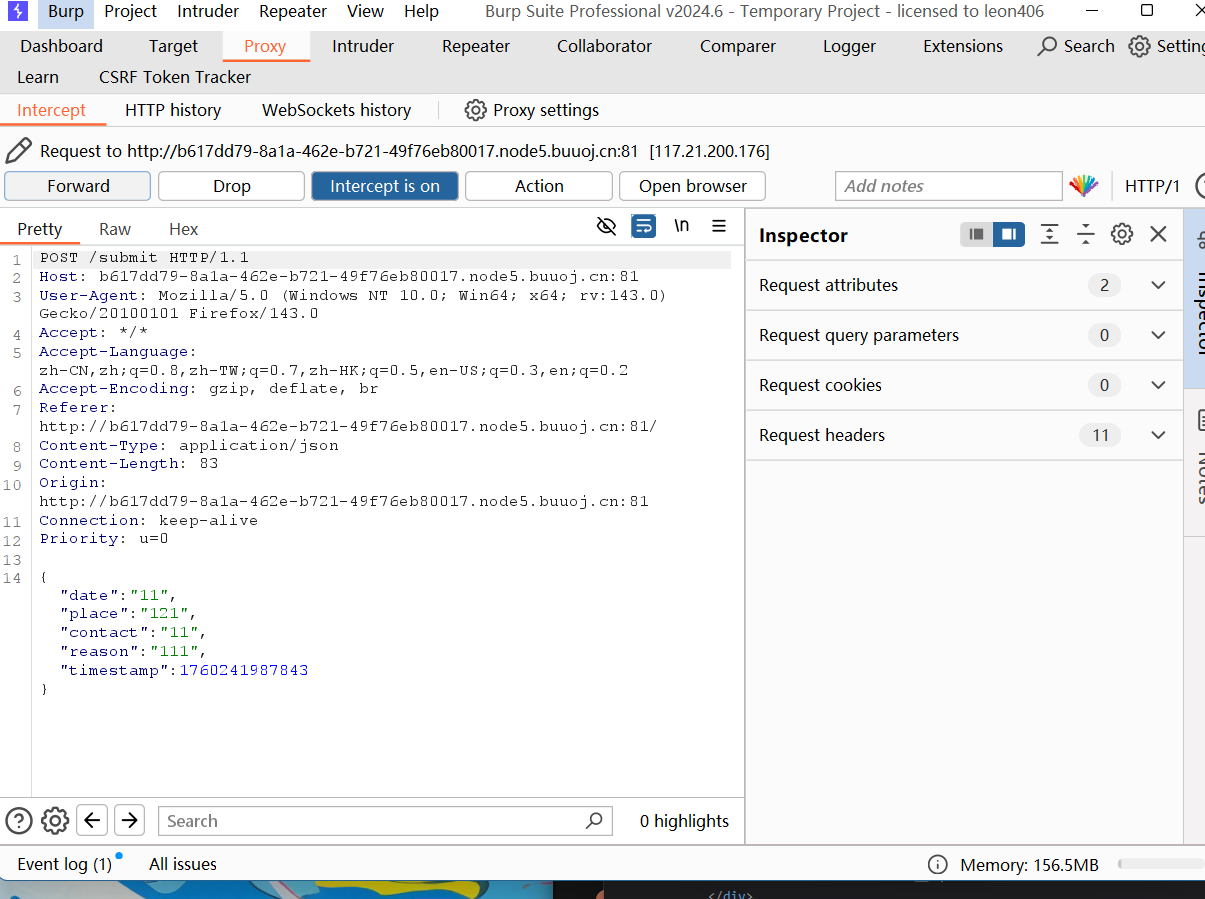
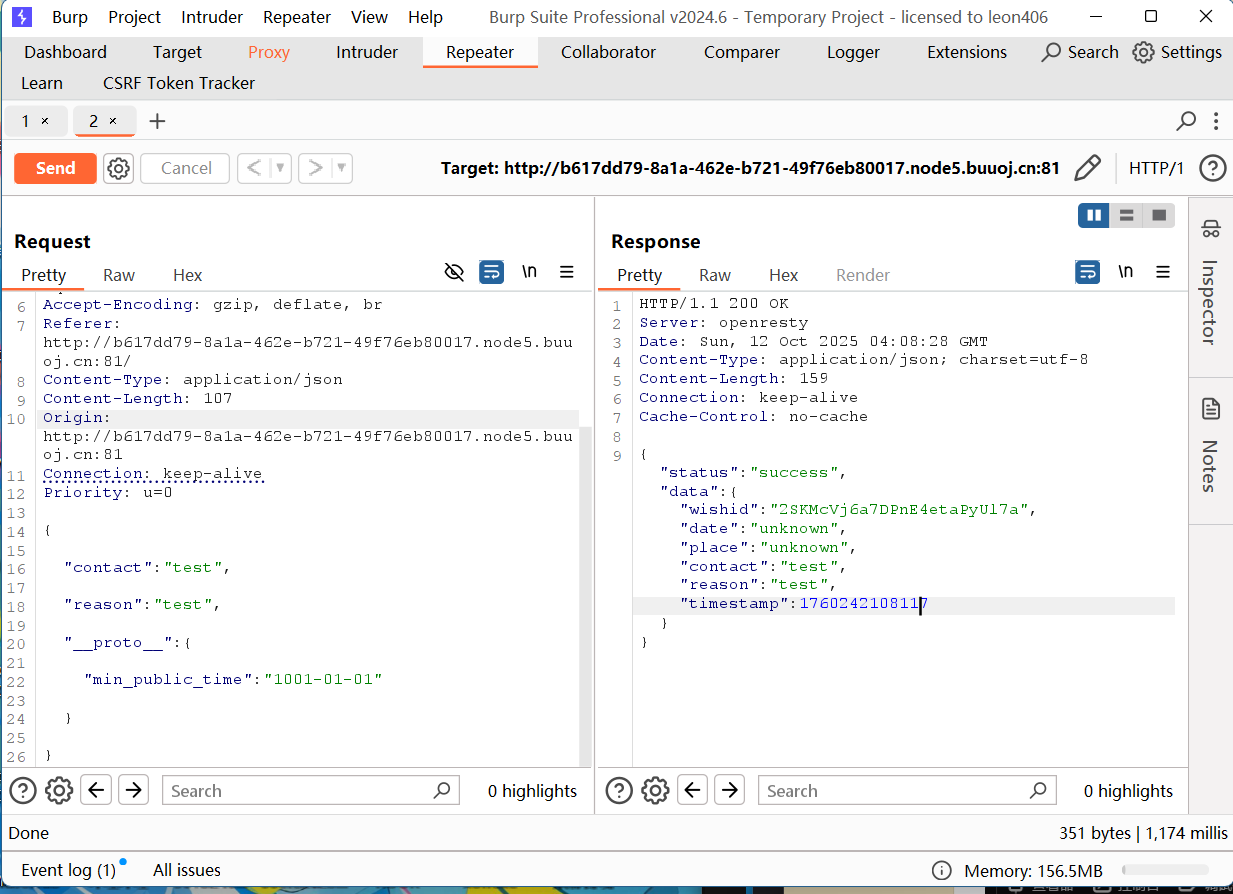
1 | { |
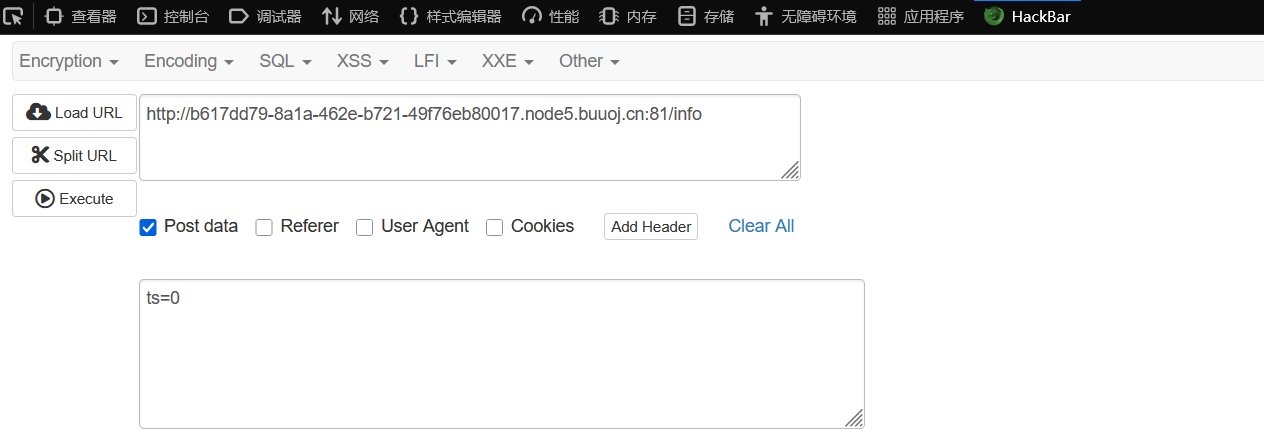
我们直接hackbar上在info路由上传ts=0,获取全部信息,最终发现其中一个含flag的信息:
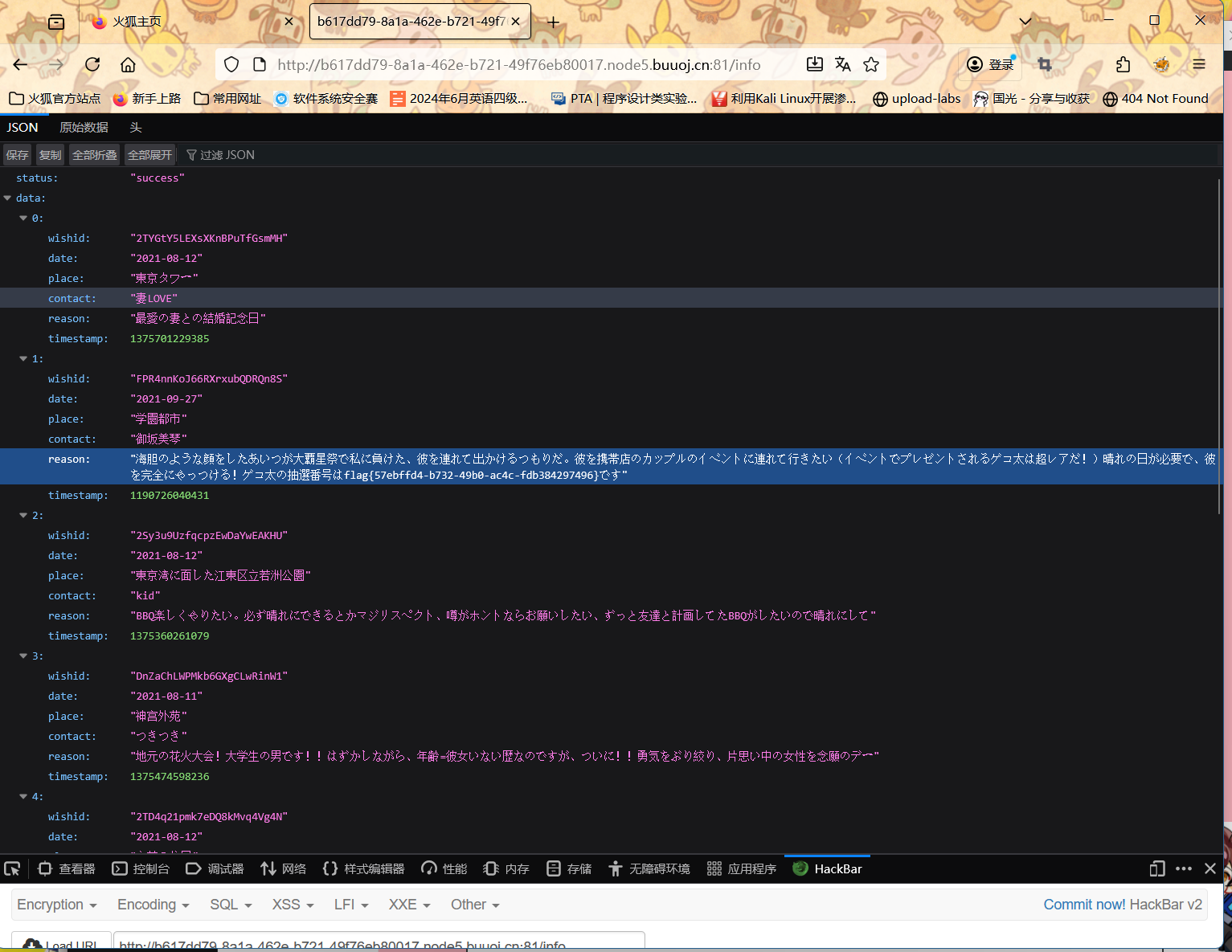
为什么要请求info
/info 这类路径通常是服务端设计的信息查询接口,用于返回特定的数据集或详情
[NewStarCTF 2023 公开赛道]OtenkiBoy
是week3中Otenkgirl的升级版 但难度差的不是一星半点哈哈
依旧是来看两个主要的js
info.js
1 | async function getInfo(timestamp) { |
截出来了主要的这个getinfo函数
负责计算查询的最小时间戳(mintimestamp)
具体步骤拆解在代码块里
后面的post是一个接口定义
通过 router.post 定义接口,处理客户端的 POST 请求
这个时间戳和createdate函数有关 所以我们再去看一下这个函数(utils.js)
1 | const createDate = (str, opts) => { |
漏洞利用点:若通过原型污染注入opts.format(如"yy19-MM-ddTHH:mm:ss.fffZ"),会篡改时间解析规则 —— 例如将"2019-07-08..."中的"20"当作yy(按规则,yy小于 100 时解析为1900+yy,即1920,最终得到更早的时间)。
可以看到createDate函数能够接受两个参数,如果没有传入opts参数,那么直接返回,没有可操作的地方,因此在gitInfo函数中,如果createDate函数的返回值没问题,那么全剧终,利用不了一点,但是如果有问题的话,就会调用catch中的代码,此时是会传入一个opts参数的,因此,第一个目标就是要让createDate函数的返回值出错。
详细来看
minTimestamp = createDate(CONFIG.min_public_time).getTime();
此时 createDate 会用默认配置(CopiedDefaultOptions)解析时间,且默认配置通常是合法的(比如 format 是标准的 "yyyy-MM-ddTHH:mm:ss.fffZ")。
只要 CONFIG.min_public_time 格式正常(比如 "2023-10-01T00:00:00.000Z"),createDate 就能生成有效的 Date 对象,getTime() 会返回正常时间戳 —— 后续逻辑按正常流程走,没有漏洞利用的机会
要触发 catch 分支,必须让 createDate 的执行结果满足以下任一条件
- 生成的
Date对象是无效的(new Date(...)结果为Invalid Date),调用getTime()会返回NaN; getTime()返回的时间戳不是 “安全整数”(!Number.isSafeInteger(minTimestamp)),直接抛出错误。
最容易通过原型污染实现的是第一种让 createDate 生成 Invalid Date。
如何通过原型污染让 createDate 出错?
关键是污染 createDate 中用于解析时间的核心配置 ——baseDate
createDate 中有一行处理 baseDate 的代码
1 | // createDate 中:baseDate 未定义时用当前时间,否则转为 Date 对象 |
当我们通过 /submit 接口的 mergeJSON 函数,污染全局原型 Object.prototype 时
1 | // 恶意 JSON 中的污染代码 |
这样一来,所有对象(包括 createDate 中的 opts)都会继承这个 baseDate: "invalid-date"。
payload
1 | { |
污染database和fff来绕过format模式——》
污染format模板使他可以以yy模式匹配min_public_time: “2019-07-08T16:00:00.000Z”——》
将createData返回的时间成功改为1919-07-08T16:00:00.000Z
不行了其实我整个思路比较乱
NewStar2023 web-week4-wp - Eddie_Murphy - 博客园
贴一个别人的wp
磕磕绊绊的也算是复现完了




